除了在機器學習與深度學習的演算法,
其實還有一些演算法,可以幫忙做資料整理,
或是進行推導,尋找關聯性,
像是這篇介紹的Apriori Algorithm。
也有些演算法像是基因演算法,能用來解決困難的數學問題,
,持續優化尋找更佳的解來解方程式。
那這裡使用mlxtend這個套件,進行安裝:
pip install mlxtend
接著可以看官網的範例:
http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
dataset = [['Milk', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Dill', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Kidney Beans', 'Eggs'],
['Milk', 'Unicorn', 'Corn', 'Kidney Beans', 'Yogurt'],
['Corn', 'Onion', 'Onion', 'Kidney Beans', 'Ice cream', 'Eggs']]
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
print(df)
dataset為顧客的購買資料,有客人可能買了五樣商品,有人買了七樣。

將資料格式使用TransactionEncoder轉換成布林值的one_hot_encoder。
from mlxtend.frequent_patterns import apriori
result = apriori(df, use_colnames=True)
print(result)
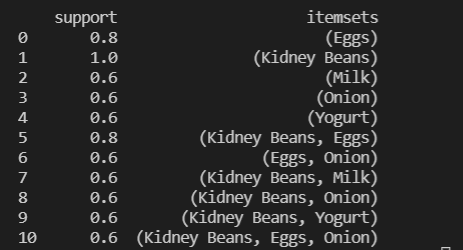
可以發現Eggs、 Kidney Beans,這兩個商品的關聯度是最大的,
可以考慮是否將兩個商品排近一點或是一起買的話祭出優惠。
值得注意的是apriori()這個function能設定最低支持度(min_support)這個參數,都不設定的話,
預設值為0.5。調太高的話,門檻越嚴格,回傳項目越少。
那我們也可以進一步將詳細的關聯規則,進一步印出。
from mlxtend.frequent_patterns import association_rules
return_association_rule = association_rules(result, metric="confidence", min_threshold=0.7)
print(return_association_rule)


 iThome鐵人賽
iThome鐵人賽